It all started last Sunday evening (at this point it was probably many Sundays ago), we were discussing cross-site scripting attacks in class when a seemingly innocent question arose:
“Which is a better way of preventing XSS attacks? Input validation or output escaping?”
We had been taking cyber security classes for two and a half years, it had been drilled into us that every piece of input should be validated at all times, you never know what’s going to come across the wire. Most of us had never even heard of, or considered, output escaping. We confidently retorted that input validation was the way to go, and not only that, but that we had yet to read anything to the contrary. After all, GIGO, right? Garbage-in, garbage-out, eye-for-an-eye, you send me bad stuff, I’ll protect myself, but if you go down in flames, not my prob... We waited for the gold star, but wound up in detention.
With a slightly disappointed (How could they possibly not know this) tone the professor informed us:
“Well, actually, output escaping is considered to be one of the best methods for defeating XSS based attacks...”
Jaws agape, we sputtered for arguments, searching for a handhold, anything to prove that the two years of classes had not been in vain. We argued about the definition of input, we argued about what output was, and who the user was, we went round and round, but eventually it started to sink in. Maybe, just maybe, this professor of ours might know something (of course he does, he’s teaching us right?). We settled into the reality that we were probably (definitely) wrong. It was time to crack the books, and surf the web for more knowledge. Luckily the professor provided us a few starting points:
It was a great start, so we shook off our defeat in class, gathered our wits, and stuck our collective noses to the grindstone. If we were going to be wrong, we were at least going to learn from it.
And learn we did. We found numerous other articles regarding output escaping, we learned that you may not always know or care where the data comes from, but that you should always know or care how that data is processed and displayed to the end user.
Sweet, this sounds easy, simply output escape everything! Unfortunately, output escaping almost seems to be a figment of the internet’s imagination, or the latest buzzword for the conference room bingo cards. There appears to be no consensus regarding the proper way to implement output escaping out there, and many old programming languages contain little to no built in libraries to support this type of functionality. Some of the newer languages like Ruby and Python do contain some basic built in html, json, and string escaping, but the documentation on how to use it properly is lacking.
So how do we do this? It is one thing to say “Escape All Output”, and quite another thing entirely to actually implement it. At this point we almost felt like we were back at square one.
So first things first...what is output escaping and how is it different from input validation? Usually when you ask someone what input validation is, they tell you it's making sure that the data is safe for the application, i.e. eliminating control and metacharacters, bounds checking, type checking, encoding, etc. If you ask them about output escaping, they give you a blank stare. Based on our readings, the clearest definitions for output escaping and input validation are as follows:
Input Validation (Data Validation): The data validation step is the process of ensuring untrusted data is in a form that expected by the application for proper processing, and will not cause the application to behave in an insecure way.
Output Escaping (Data Neutralization): The data neutralization step is the process by which we ensure that the untrusted data can be safely passed along to other applications and is free of any attacks.
Just to shake things up, we would like to add a third definition for “data context”, meaning that data is complete, in its final form, and ready to be passed on. Why is this important? Because anything done to data prior to its context being understood risks corrupting the data, or attempting to validate partial information. Chew on that for a second....
Clear as mud, amirite? However some deeper reading helps us further elaborate on our definitions. Per the article by Guy-Vincent Jourdan for the Open Software Engineering Journal (pdf), the input validation step is here to protect our application itself, whereas the data neutralization step is focused on protecting other applications that are using data from our application.
To illustrate the difficulties with the two techniques, we refer again to the article by Guy-Vincent Jourdan. In this article, the author does a decent job of portraying the challenges of managing data as it traverses from user injection point, through the potential myriad of applications and modules, before ever arriving at the desired output interface. For example, the following diagram depicts a potential web-based application and the potential flow of data throughout the application.
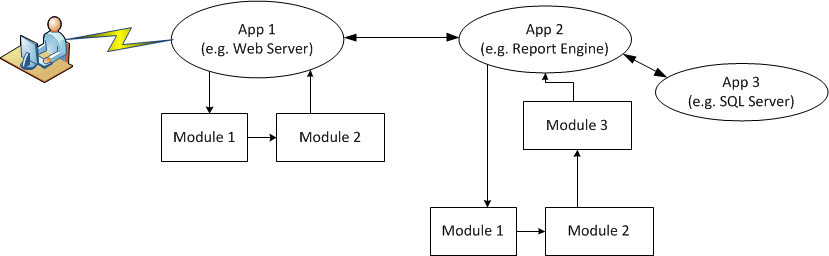
The user might enter input via the web browser, which is received by the web server, which then processes it in some fashion sending that data to a module, which forwards to another module, then to a reporting application where the data is mixed with some stored data, then returned to the end-user. At each interface, the data can be considered “input” or “output” depending upon the context/viewpoint of the sender/receiver.
This naturally caused us to ask the question “Do we have to output escape at each handoff between applications? Where exactly do we conduct input validation and output escaping?”
The short answer: In our input validation step, we do not attempt to protect from injection at all. And why should we? In and of itself, there is no risk in simply passing data along. The risk comes when we decide to process or apply it. For these reasons, it is recommended that you wait until the data is in its full context and inside the module that will eventually use it before conducting validation. In other words, we are treating the input validation step as normal software development best practices, i.e. validate the type, the range, ensure enough memory exists, etc., and do it as late as possible.
Now that we cleared up input validation, lets talk a bit more about how and where output escaping occurs. Much like the input validation step, output escaping should not be done prior to the full context of the data is clarified. This generally occurs when the data is ready to be sent from our application to another application. Typical steps here are to use things like white and black lists to allow known good inputs and filter/encode/escape known bad inputs. Even better, now that we know the context that the data is going to be used in, we can apply the above techniques smartly so that we are escaping output in the right way for the destination application.
To go a bit deeper still, we now refer to OWASP. OWASP (The Open Web Application Security Project) has a list of 10 XSS Prevention Rules (helpfully named 0-7 :) ) that detail the steps one needs to consider before placing any untrusted data in an output document. The guts of these rules are more technical than we wish to address in this blog post, but can be summarized by Rule 0: “Never Insert Untrusted Data Except in Allowed Locations”. Basically, you want to be very careful where you insert user (read as untrusted) data. If you choose to follow the OWASP XSS Prevention Rules, most of the time when inserting data you will need to escape it first. Though there are some places where if you allow user data at all, you’re vulnerable to XSS attack. In fact, OWASP specifically calls out the javascript function window.setInterval:
<script>
window.setInterval('..EVEN IF YOU ESCAPE UNTRUSTED DATA YOU ARE XSSED HERE..');
</script>
window.setInterval('..EVEN IF YOU ESCAPE UNTRUSTED DATA YOU ARE XSSED HERE..');
</script>
According to OWASP the goal of output escaping is to convert untrusted input into a safe form so that the input can be displayed as data to the user without executing as code in the browser. To this end OWASP provides the following suggestions for encoding mechanisms to prevent XSS:
Encoding Type
|
Encoding Mechanism
|
HTML Entity Encoding
|
Convert & to &
Convert < to <
Convert > to >
Convert " to "
Convert ' to '
Convert / to /
|
HTML Attribute Encoding
|
Except for alphanumeric characters, escape all characters with the HTML Entity &#xHH; format, including spaces. (HH = Hex Value)
|
URL Encoding
|
Standard percent encoding, see: http://www.w3schools.com/tags/ref_urlencode.asp
|
JavaScript Encoding
|
Except for alphanumeric characters, escape all characters with the \uXXXX unicode escaping format (X = Integer).
|
CSS Hex Encoding
|
CSS escaping supports \XX and \XXXXXX. Using a two character escape can cause problems if the next character continues the escape sequence. There are two solutions (a) Add a space after the CSS escape (will be ignored by the CSS parser) (b) use the full amount of CSS escaping possible by zero padding the value.
|
This output escaping is performed at the presentation layer, just before it’s passed to the end user. That end user may be a web browser, or another system accessing the data via a REST or API call with a JSON or XML response. In both cases you need to properly escape the output so that the end user in all cases is protected from XSS (or other display based) attacks. In the case of the JSON response, the receiving system can always choose to unescape the received data. In the case of the browser, the data is properly received as data and not as code, and the user is protected from XSS attacks. The output escaping can be tailored to meet the needs of the output destination, while the JSON response may only require simple escaping that can be applied across the entire document evenly, the web browser response will most likely require escaping that is particularly tailored to how the data is used in each piece of the html response.
Ultimately, there may be many different libraries or tools available for implementing output escaping, however, reviewing the OWASP XSS Prevention Rules Cheat Sheet can help you to determine the best code location where untrusted data needs to be escaped and how to escape it properly. Escaping is vital, and for good reason, by allowing arbitrary code to be displayed alongside your code, you give an attacker full control over what is served via your webpage. User input should be treated as data, and never given the chance to be executed as code. You escape at the last moment before display, you know the proper context of all your user data, and you know where it’s safe to put it.
Now this is starting to make more sense and dare we say it, its actually pretty neat. In most basic terms, we should use output escaping as the primary defense against cross site scripting, and use input validation to add a defense in depth aspect to our application security. This strategy is sound, makes sense, and feels intuitively right. At the end of the day, each developer needs to understand the distinctions between input validation and output escaping, so that these techniques can be properly applied, thereby protecting us users.
So, why should we bother output escaping????
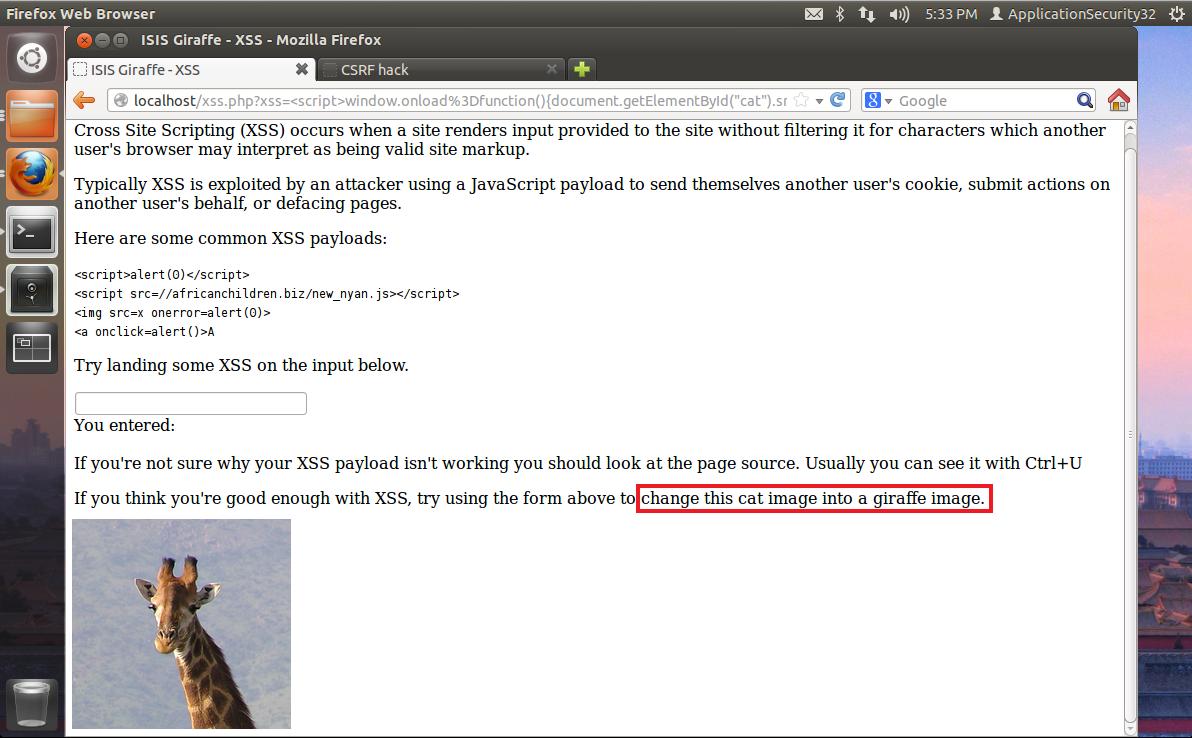
(Because some images you just don’t want on your website.)
Giraffe Image Source: http://en.wikipedia.org/wiki/File:Giraffe_standing.jpg
{kind=link}
Just in case you’re still awake and interested, here’s some additional reading: